
Ever wondered how some chatbots seem to know exactly what you’re looking for, even when your question is a bit vague? Or how certain applications can pull relevant information from vast document libraries almost instantly? The secret sauce is often a technique called Retrieval-Augmented Generation, or RAG. This article provides a comprehensive explanation of RAG and all its intricacies, moving from the basic concept to its benefits and the challenges. We’ll explore how it works, its real-world applications, and what makes it such a significant advancement in the field of natural language processing.
1. Defining Retrieval-Augmented Generation (RAG)
RAG is a framework in where the primary goal is to improve quality of answer generation by language models (LMs) by grounding its responses on external knowledge, and improving the verifiability. It combines the strengths of two prominent methods, information retrieval and text generation. Before now, large LMs were trained on massive datasets, but their knowledge remained fixed at the point of training. If you asked a question about a recent event that happened after training, it wouldn’t know the answer. Or worse, it might “hallucinate” a response – fabricate something the model that sounds believeable , but is entirely incorrect.
RAG provides a solution. It first retrieves relevant documents or data snippets from a knowledge base (this could be a database of documents, a knowledge graph, or even the web). Then, it augments a generative LM with this retrieved information. This means the LM doesn’t just rely on its internal, pre-trained knowledge; it has access to up-to-date a extra factual data. The model then generation a response based on. Combining both the retrieved context and its pre-existing.
This process is analogous to researching a topic before writing an essay. You wouldn’t just write from memory, you’d gather information from books, articles, and other sources. RAG gives LMs a similar capability.
2. How RAG Works: A Step-by-Step Breakdown
The RAG process can generally be broken down into three central steps:
2.1. Retrieval: Finding the Relevant Information
The first stage involves an incoming query. This could be in the form of an user question, a prompt, or some other input that an answer will be needed for. The retrieval mechanism takes this query and searches a pre-defined knowledge source. The most common form is the “dense passage retrieval” (DPR) the system. With DPR, both the documents in the knowledge source and the user’s query are transformed into numerical representations (vectors or embeddings) using a neural network (often a type of model called a “transformer”).
These vectors represent the meaning of the text. Vectors that are close to each other in this vector space are semantically similar. The retrieval system then finds the documents whose vectors are closest to the query’s vector. This means the system is finding documents that are the most topically related to the query, not just those that share the same keywords.
2.2. Augmentation: Combining Knowledge
Once the system has retrieved relevant document. They’re fed into the LM along with, the original query. This is the “augmentation” part of RAG. The way this is done can the models vary, but a common approach is to simply concatenate (join together) the query and the retrieved documents into a single input sequence for the LM. it is the difference of adding reference material to your model or not, significantly improving quality.
2.3. Generation: Crafting the Response
The final step is the text generation. One language model, now infused with knowledge from the retrieved documents, produces a natural language response. Since the model uses both its pre-existing knowledge to make the response, along with the added context, makes it more likely to be factually correct, and relevant.
3. Key Benefits of Using RAG
One of the primary advantages of RAG is its ability to increase the accuracy and reliability of responses for the model. By grounding the LM in external knowledge, it reduces the likelihood to the model of generating factually incorrect information (“hallucinations”). This is especially valuable when dealing with questions that require up-to-date-information or domain-specific expertise.
Another benefit is the improvement of contextual understanding. The retrieved documents provide additional context to the LM, allowing it to better understand the nuances of the query and generate more relevant answers. This lead to better results with user satisfaction since queries are better understood.
RAG also improved the transparency and explainability of LM responses. Because the output is based, in part, on retrieved documents, it’s often possible to trace the source of the information. This is a significant advantage over “black box” LMs where it’s difficulty to understand why a particular response was generated.
Finally, RAG allows models to be more easily updated with new information. Instead of retraining the entire LM (which is can be computationally expensive and time-consuming), only by updating the knowledge source. This makes RAG a more practical solution for real-world applications where knowledge is constantly evolving.
4. Practical Applications of RAG
RAG is increasingly used in various of applications where accurate, contextual, and up-to-date information is crucial.
4.1. Question Answering Systems
One of the most prominent applications is in question answering systems. RAG can significantly improve the performance of chatbots, virtual assistants, and search engines. It’s enabling them to provide more informative and accurate answers to user queries, even on complex or niche topics.
4.2. Content Creation and Summarization
RAG can also assists in content a task, such as generating news articles, writing reports, or creating product descriptions. By retrieving relvant information from various sources, RAG can help models output detailed and factually sound content. it also be used for text, pulling in main points of the text, and generating it as a summary.
4.3. Research and Development
In scientific research and development, RAG can be used to analyze large sets of research papers, patents, and other a document. To quick access to specific details and a summary to streamline literature review process.
4.4. Customer Service enhanced for busines
RAG is used to improve customer service by enabling chatbots to access product manuals, FAQs, and troubleshooting guides. This allows them to provide more comprehensive an helpful. to client queries.
5. Challenges in Implementing RAG
While RAG is an impressive advancement , there exist challenges in its implementation:
5.1. Retrieval Accuracy
The effectiveness of RAG substantially depend on the quality of the retrieval component. If the retrieval system fails to find the most relevant documents, the generated response may be incorrect. Improving the accuracy and efficiency of retrieval is a continuous area for research.
5.2. Computational Resources
RAG models can be computationally intensive, requiring significant processing power and memory. This can be a barrier to adoption, particularly for organizations with limited resources. Optimizing models for efficiency and exploring techniques like knowledge distillation.
5.3. Bias and Fairness
Like all forms of AI, RAG models will be susceptible to biases present in the data they are trained on or in the knowledge sources they utilize. If the knowledge source contains biased information, the generated responses will be reflective of that. Addressing bias and ensuring fairness require meticulous data curation and model evaluation.
5.4. Scalability Challenges
Scaling RAG systems to handle extremely large and constantly changing knowledge sources is a significant challenge. Efficient indexing, retrieval, and maintenance of these massive datasets are complex engineering problems. There needs to be careful planning, for data maintenance for the RAG system.
6. Future Directions for RAG
The field of RAG is rapidly evolving, with ongoing research focused on several keys areas:
6.1. Multimodal RAG
Current RAG models primarily handle text. However, it’s an increasing interest in developing multimodal RAG systems that can retrieve and generate content from multiple modalities, such as images, audio, and video.
6.2. Improved Retrieval Techniques
Research continues to improve retrieval methods, exploring techniques like iterative retrieval (where the retrieval process is refined based on the generated output) and knowledge graph retrieval (where the knowledge source is a structured knowledge graph instead of a collection of documents).
6.3. Integration with Other AI Techniques
Combining RAG with other AI techniques, such as reinforcement learning and transfer learning, could further better LM’s, leading to even better accuracy, and versatility.
6.4. Long-Form Text Generation
Extending RAG to a model, for complex and creative content, such as writing entire multi page essays, or generating full dialogue for interactive role-playing games, is another of research.
Here’s a visual representation on how RAG works:
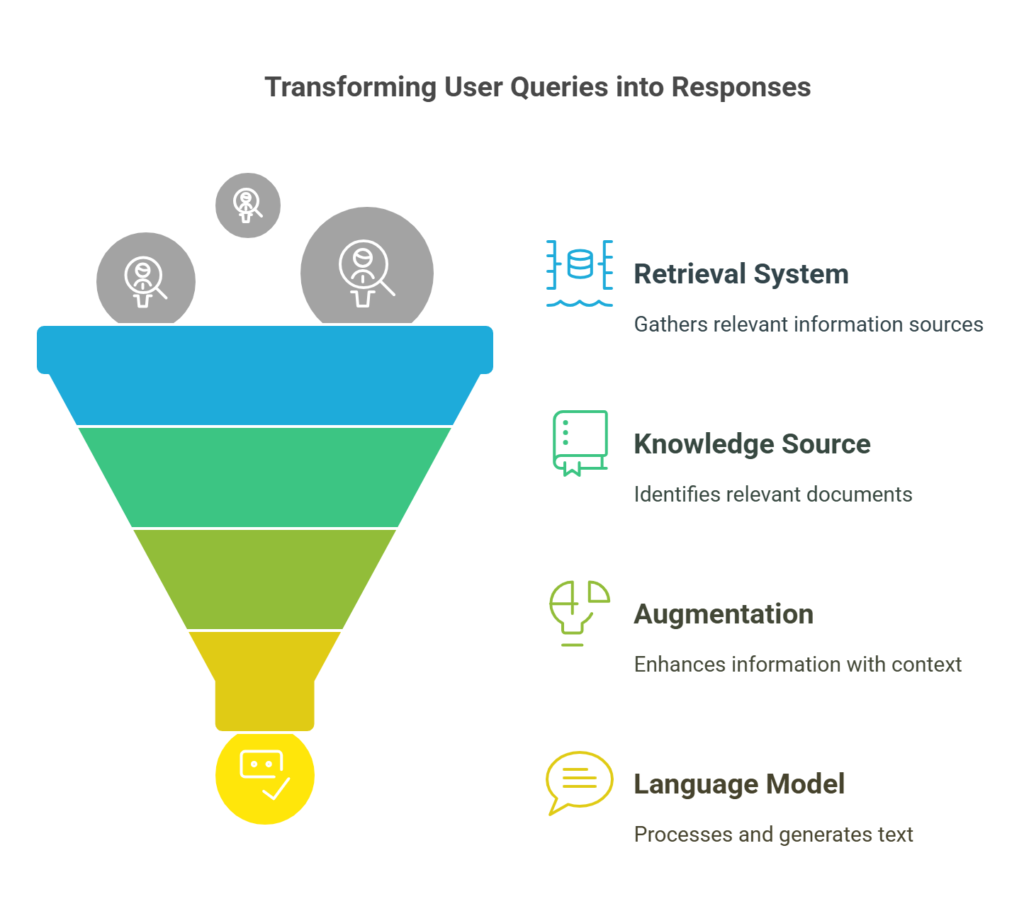
Diagram 1 Description: This flowchart Illustrates the RAG process. The user query goes to both the retrieval system and the augmentation step. the retrieval system accesses. The knowledge source, to retrieve key information, and finally generation of a response.
Here’s another Visual representation:
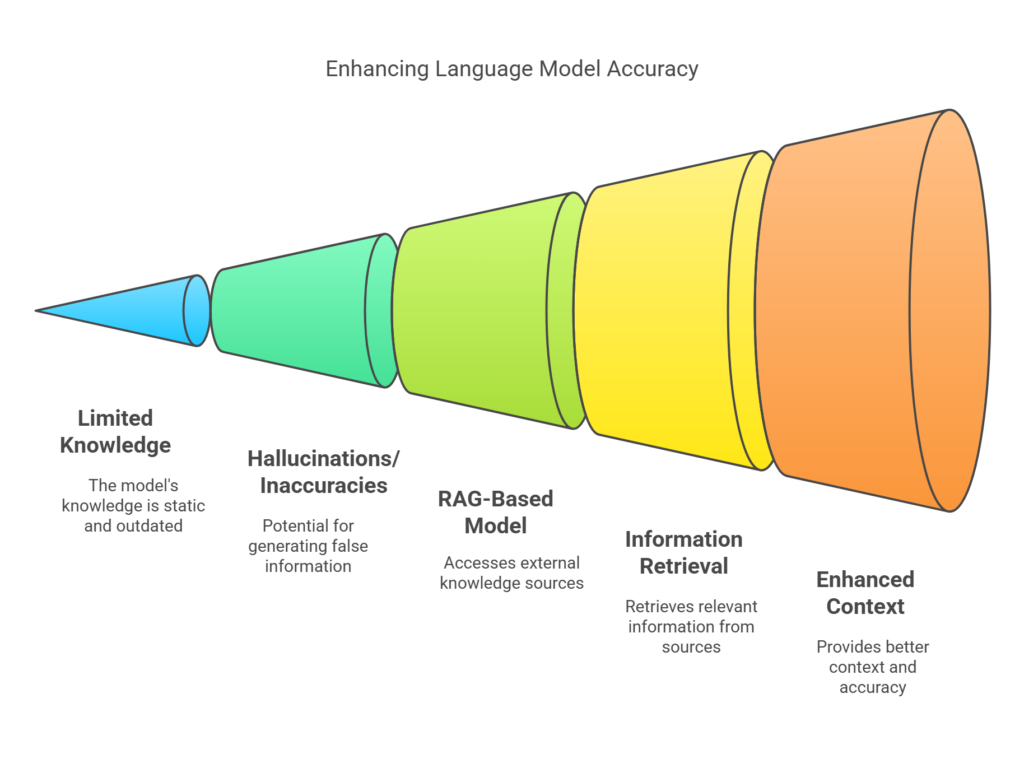
Diagram 2 Description: This comparison chart. Traditional Language Model and a RAG-Based Language. Model. Highlighting the limitation for the standard model, and RAG’s advantage.
7. Key Takeaways
- RAG (Retrieval-Augmented Generation) improves language models by grounding them in external knowledge.
- The process involves retrieving relevant information, augmenting the model, and generating a response.
- Key benefits include increased accuracy, improved contextual understanding, and a greater transparency.
- RAG has applied uses in question answering, content, and research.
- Challenges involve retrieval accuracy, computational issues, biase fairness, and scaling.
- Future directions include multimodal RAG, improved retrieval techniques, and integration with other AI methods.
- Its ability helps improve the models performance, and keep it update to date.
8. Conclusion
Retrieval-Augmented Generation (RAG) represents one of the impressive advancement, in the development in of language models. By combining the strength of retrieval and generation, RAG overcomes many of the limitations of traditional LMs’s accuracy, reliability, and contextual awareness. While a challenge remain, ongoing research of RAG models is set to play an important role in the future of the technology, enabling the development of more powerful, versatile, and trustworthy.
9. Frequently Asked Questions about RAG
Q1: What’s the main difference between RAG and fine-tuning?
A1: Fine-tuning updates the model’s weights to a certain task of dataset, while RAG adds an external knowledge source to assist with answering without changing the model’s core weights.
Q2: Can RAG be used with any language model?
A2: In the real world, RAG can be adapted to work to various of language model architectures, although some perform better than others to this technique.
Q3: How does RAG handle conflicting information from different sources?
A3: This is a challenging question. The strategy of using RAG models include ranking sources by reliability, or other advanced model architectures.
Q4: What are some popular libraries or frameworks that support RAG?
A4: Frameworks like LangChain and libraries like FAISS (a library for efficient similarity search) are commonly used for implementing the components of RAG.
Q5: Is the utilization of RAG suitable for real time applacation?
A5: Yes, although there can be, computation. Optimizations in retrieval and generation can make RAG fast enough for many real.


